Coinbase率先采用中国开源AI模型GLM与Kimi,大幅降低AI运营成本
美国科技企业转向中国AI模型
美国科技企业正悄然将中国开源人工智能模型纳入其生产基础设施。面对顶尖美国AI模型服务成本持续攀升的压力,以加密货币交易平台Coinbase为代表的企业开始将中国开源模型作为默认选项,在不压制使用量的前提下显著压缩AI开支。
Coinbase部署GLM与Kimi为默认模型
Coinbase首席执行官Brian Armstrong于上周五晚间在X平台发文披露,公司已通过内部LLM网关,将智谱AI发布的GLM 5.2以及北京月之暗面推出的Kimi 2.7设定为工程师的默认AI模型。Armstrong表示,在结合智能路由、缓存改进等技术手段后,Coinbase的AI支出已削减“近一半”,而token使用量仍在以指数级速度增长。
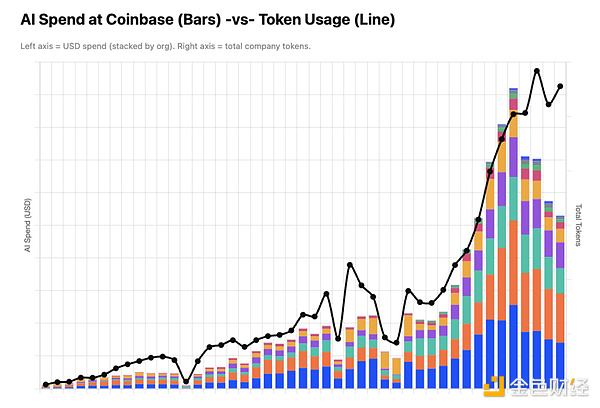
成本优势驱动模型切换
Armstrong指出,91%的工程师从未触及原有的AI使用上限,因此Coinbase并未选择限制用量或增设消费提醒,而是直接转向“更便宜的默认模型”。GLM 5.2和Kimi 2.7均为开源权重模型,适用于常规任务场景。对于需要复杂推理或规划的任务,工程师仍可调用前沿闭源模型。Armstrong强调,在执行层面使用顶级模型往往是“大材小用”。
多模型并行保障代码质量
在关键的代码审查环节,Coinbase采用多模型并行策略,让不同AI模型相互校验输出结果,以维持高质量标准。这一做法既利用了低成本模型的经济性,又确保了关键流程的可靠性。
三层架构实现成本优化
Armstrong列出了驱动成本削减的三大核心措施:
- 智能路由:在自定义调度框架中,系统对提示词进行预处理,综合缓存命中率与模型定价,自动将任务分发至最经济、合适的模型,目标是让AI自主完成模型选择。
- 积极缓存:所有请求均具备缓存感知能力,最大限度复用已有结果。以LibreChat为例,正确实施缓存机制后,缓存命中率从5%跃升至60%。
- 精简上下文:建议工程师在切换任务时开启新会话、缩小文件上下文范围、断开未使用的工具连接,旨在减少“被浪费的token”,而非单纯降低总用量。
效率优先,扩大AI采用规模
Armstrong强调,此次成本压缩并非限制AI使用,而是为扩大AI采用规模创造前提条件。工程师仍可自由使用任意数量的token和任意模型,但公司已将用量数据可视化,并将使用量与业务影响挂钩——“花得越多,我们期望的影响也越大”。尽管未披露具体支出数字,但在使用量指数增长的同时实现近半成本削减,表明Coinbase已在一定程度上实现了AI消耗与成本的解耦。
方法论具普适性
Armstrong总结称,这套AI基础设施优化方法论具有广泛适用性,任何企业均可借鉴,以便在不将成本设为天花板的前提下,实现AI使用规模的可持续扩张。
- 22 分钟前现货金银短线下挫,现货黄金跌幅扩大至0.6%
- 23 分钟前美联储7月维持利率不变的概率为69.5%
- 24 分钟前美股三大股指期货盘初小幅拉升,纳指期货现涨0.4%
- 1小时前GWEI突破0.165美元,24小时涨幅达28.51%
- 1小时前普京:俄建议乌俄双方均停止打击对方领土纵深目标
- 2小时前美媒:美伊同意停止互袭 本周将在卡塔尔会晤





