正文
Anthropic工程师揭秘:如何通过缓存机制一周节省3亿Token
编辑:Luna发布时间:8小时前
引言:Token消耗问题与解决方案
许多用户在使用Claude Code时,常常感到Token消耗过快,尤其是在长时间会话中。然而,从Anthropic工程师的角度来看,真正影响成本的并非代码量,而是系统是否能有效复用已处理的上下文。本文将探讨如何通过缓存机制显著降低Token消耗。
核心概念:Prompt Caching的作用与成本优势
Prompt caching的核心在于“不要打断缓存”。Claude Code会分层缓存系统提示、工具定义、CLAUDE.md、项目规则和历史对话等内容。只要后续请求的前缀保持一致,Claude可以直接读取缓存,而无需重新处理整段上下文。
缓存Token的成本仅为普通输入Token的10%。例如,作者某一天命中了9100万缓存Token,实际计费仅相当于900万普通Token。

缓存的工作原理:Prefix Matching机制
Claude Code依赖前缀匹配(prefix matching)来实现缓存复用。只要某个位置之前的内容与已缓存内容完全一致,Claude就可以复用这部分缓存Token。
一次全新会话的展开过程如下:
- 第一轮对话:没有缓存,所有内容重新处理并写入缓存。
- 第二轮对话:第一轮内容已被缓存,只需处理新回复。
- 第三轮对话:逻辑相同,只有最新交互需要重新处理。
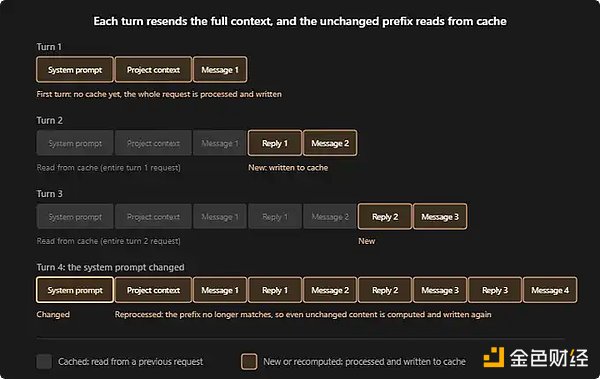
缓存的三层结构
缓存分为以下三层:
- 系统层:包括基础指令和工具定义,全局缓存。
- 项目层:包括CLAUDE.md、memory和项目规则,按项目缓存。
- 对话层:包括回复和消息,随每轮对话不断增长。

关键使用技巧:避免破坏缓存的操作
以下是几个避免破坏缓存的关键技巧:
- 不要让会话空置超过1小时。
- 切换任务时做好session handoff。
- 避免频繁切换模型。
- 大文档尽量放入Projects,而非直接粘贴到对话中。
此外,切换模型或开启“Opus plan”模式都会破坏缓存,需谨慎操作。
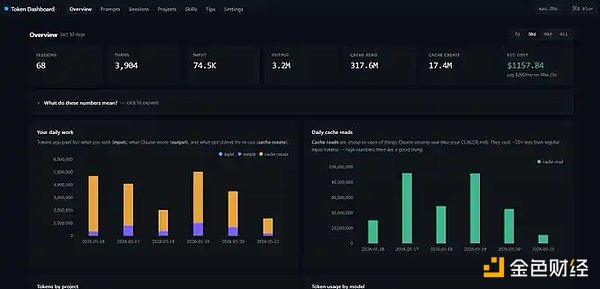
缓存统计工具:Token Dashboard
作者使用了一个名为Token Dashboard的工具来监控缓存数据。该工具可以读取过去的所有会话记录,并显示每天的input、output、cache create和cache read数据。
GitHub仓库链接:https://github.com/nateherkai/token-dashboard
总结:掌握80/20法则,高效利用缓存
你不需要完全理解缓存的所有细节,只需掌握以下几个关键点:
- 缓存Token比普通Token便宜10倍。
- Claude Code的TTL为1小时。
- 切换模型会破坏缓存。
- 在任务之间做好清晰交接,通常比硬接着旧会话更划算。
通过这些简单的调整,你可以显著延长会话额度,同时降低使用成本。





