91% 存在漏洞、94% 可被投毒——AI Agent 安全问题敲响警钟
AI Agent 安全现状:漏洞无处不在
自主 AI Agent 正以惊人速度渗透医疗、金融和企业运营,但迄今最大规模的安全研究表明:绝大多数在生产环境运行的 Agent 存在严重漏洞,而当前主流安全评估手段对此几乎束手无策。
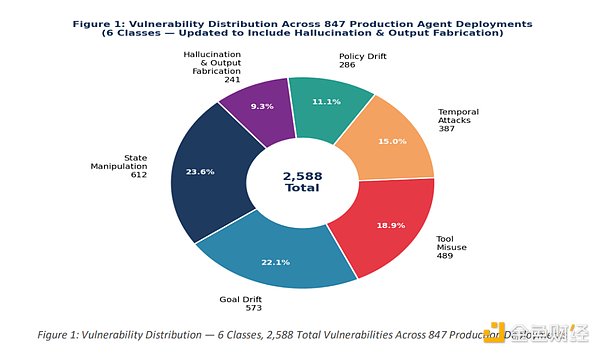
近期,斯坦福大学、MIT CSAIL、卡内基梅隆大学、ITU 哥本哈根及 NVIDIA 的联合研究团队近期研究发现,在所评估的 847 个自主智能体生产部署中,91% 存在工具链攻击漏洞,89.4% 在执行约 30 步后出现目标偏移,94% 的记忆增强型智能体面临「投毒」风险。研究共发现 2,347 个此前未知漏洞,其中 23% 被评定为严重级别。
现实案例:OpenClaw/Moltbook 事件警示
论文第一作者 Owen Sakawa 援引 2026 年初的「OpenClaw/Moltbook 事件」,佐证这一威胁已从理论走入现实:Moltbook 平台数据库中的单一漏洞,导致平台上 77 万个运行中的 AI Agent 同时遭到攻陷,每个 Agent 均持有对其用户设备、电子邮件及文件的特权访问权限。「这不再是假设性威胁,」Sakawa 表示。

六类攻击分类:2347 个已知弱点
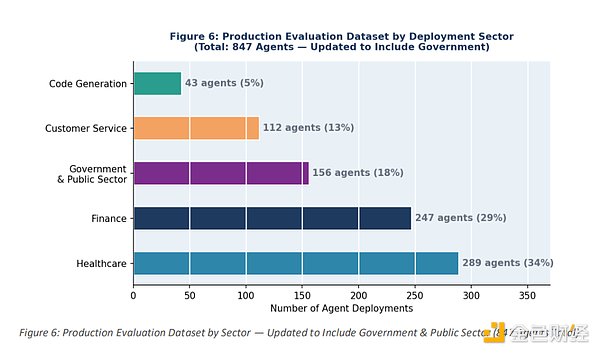
研究覆盖医疗(289 个部署,占 34.1%)、金融(247 个,占 29.2%)、客户服务(198 个,占 23.4%)及代码生成(113 个,占 13.3%)四大行业。
研究建立了一套针对自主智能体的六类漏洞分类体系,包括目标漂移与指令衰减、规划器 - 执行器去同步、工具权限提升、记忆投毒、静默多步骤策略违规,以及委托失败。
架构缺陷:为何 AI Agent 更脆弱
研究的核心论断是,自主智能体与无状态语言模型的安全挑战在性质上截然不同。针对语言模型的安全评估聚焦于「能否让模型说出不安全的内容」;而对 AI Agent 而言,问题变为「能否让模型做出不安全的事」——包括具有现实效果的工具调用、影响未来行为的状态修改,以及跨多步骤才显现违规的计划执行。
对企业部署的影响:防护框架尚不成熟
研究团队依据实证结果提出了最低安全基线:所有生产 Agent 强制部署运行时监控;对涉及数据访问后对外通信的工具链操作设置人工审批门槛;每执行 20—25 步应强制触发人工审查,以应对步骤超出后几乎必然出现的目标偏移;记忆增强型 Agent 须对持久化状态进行加密完整性校验。
随着欧盟《人工智能法案》、美国 NIST AI 风险管理框架等监管要求的落地,企业面临的合规压力与安全风险将同步上升。在 AI Agent 被广泛部署于高风险业务场景的背景下,安全基础设施的缺位,正成为这一轮 AI 商业化浪潮中不可忽视的系统性风险。





