Claude Code额度异常消耗20倍,官方回应引发争议
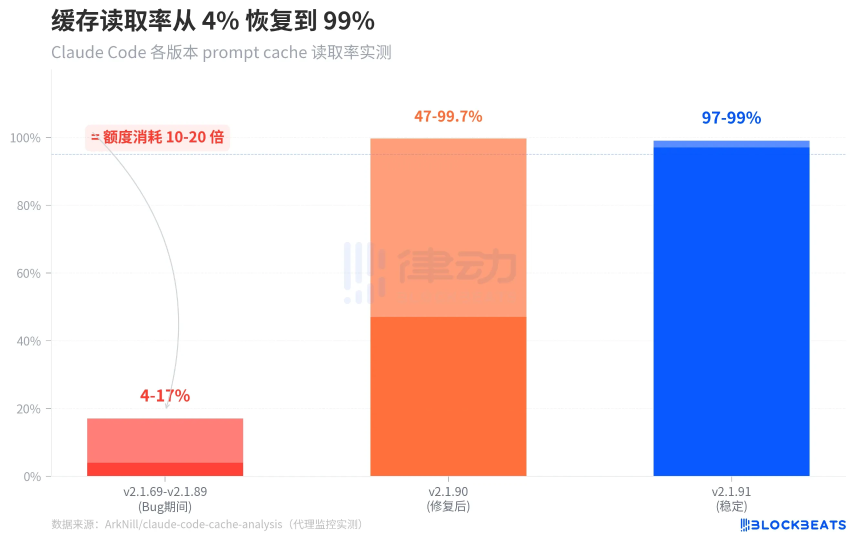
缓存读取率暴跌至4-17%
过去一个月里,Claude Code的prompt cache读取率仅为4-17%,而正常水平应为97-99%。这意味着用户在恢复会话时,系统未能复用之前处理过的上下文,而是每次都重新处理全部内容,导致消耗的额度是正常情况的10到20倍。
独立开发者揭示缓存Bug问题
独立开发者ArkNill通过设置透明代理,监控了Claude Code与Anthropic API之间的请求,发现了至少两个客户端缓存Bug,导致API服务器无法匹配已缓存的对话前缀,被迫每轮都做完整的token重建。
修复版本逐步恢复正常
在v2.1.90修复了一个关键Bug后,冷启动缓存读取率回升至47-99.7%;到v2.1.91,稳定运行下的缓存读取率恢复到97-99%。然而,在Bug版本中,缓存读取始终停留在系统提示词的14,500个token上,所有对话历史每次都按全价计费。
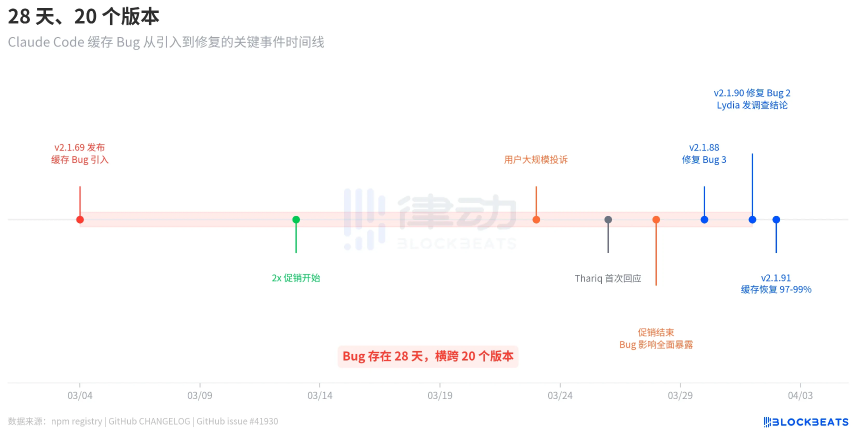
横跨28天、20个版本的Bug时间线
根据npm registry的发布记录,引入Bug的v2.1.69发布于3月4日,修复Bug的v2.1.90则发布于4月1日,中间隔了28天,横跨20个版本。值得注意的是,由于3月13日至28日期间Anthropic曾上线2倍额度促销,掩盖了Bug的影响,直到促销结束后问题才集中爆发。
Anthropic的迟缓回应与用户不满
Anthropic的官方回应并不及时。直到3月26日,工程师Thariq Shihipar才在个人X账号上宣布高峰时段限额收紧;3月30日,团队承认“用户触达限额的速度远超预期”。整个过程中,Anthropic未发布任何博客文章或邮件通知,仅通过工程师的社交媒体帖子和Reddit评论进行沟通。
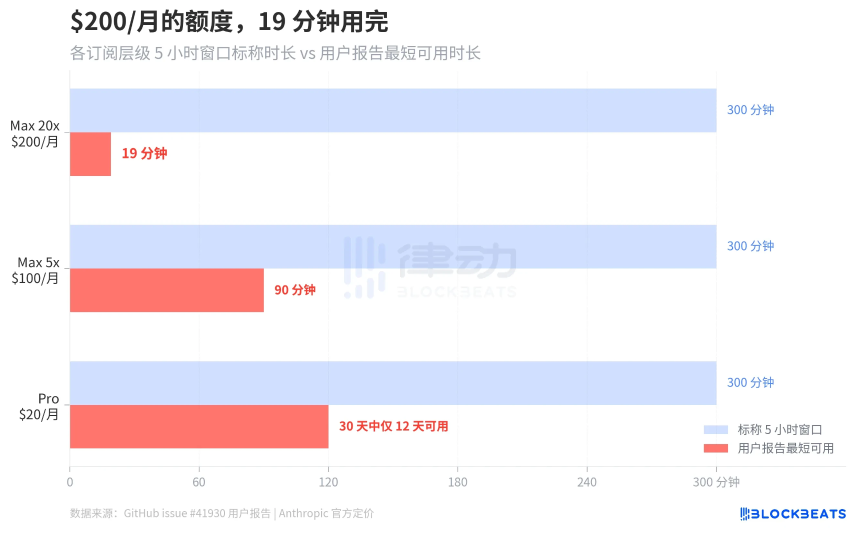
用户的极端案例与经济损失
GitHub issue #41930汇集了数百条用户报告,最极端的案例是一位Max 20x订阅用户($200/月),其5小时滚动窗口在19分钟内完全耗尽。据The Letter Two报道,还有用户称一条简单的“hello”就消耗了13%的会话配额。
官方建议引发争议
Lydia Hallie的调查结论确认了两点:一是高峰时段限额确实收紧,二是100万token上下文的会话消耗增大。她建议用户降级模型、关闭功能、限制上下文,但未提及任何形式的限额重置或补偿。

对比OpenAI的处理方式
相比之下,OpenAI在Codex出现类似额度异常消耗问题时,选择了重置用户配额、补发credits,并最终移除使用上限。Anthropic的做法则是将责任归因于用户的使用方式,引发了广泛争议。
- 3 分钟前美联储戴利:亮眼就业报告为政策制定者争取到时间
- 10 分钟前盈利超150万美元账号购入34万美元NBA常规赛76人战胜森林狼
- 18 分钟前金色晨讯 | 4月4日隔夜重要动态一览
- 46 分钟前分析师:微软的AI开发将对Azure的近期增长构成压力
- 49 分钟前美媒:调解方说停火努力陷入僵局
- 53 分钟前以色列称监测到伊朗发射的导弹 南部多地响起防空警报





